프론트엔드 개발자가 꼭 챙겨야 하는 것 중 하나는 SEO입니다.
이번에는 SEO란 무엇인지, 왜 프론트엔드에서 신경써서 챙겨야 하는지, 어떻게 신경쓸 수 있을지
그리고 CSR과 SSR를 통해 어떻게 SEO를 향상시킬 수 있는지에 대해 알아보았습니다.
SEO (Search Engine Optimization 검색 최적화)
검색 크롤러
먼저 웹 크롤러 봇에 대해 설명드리겠습니다.
웹 크롤러 봇(검색 크롤러/ 스파이더 / 검색 엔진 봇)는 웹 상의 모든 웹페이지를 돌아다니며, 그 페이지가 무엇에 대한 페이지인지 파악하여 필요할 때 정보를 추출할 수 있도록 합니다.
이렇게 소프트웨어 프로그램을 통해 자동으로 웹사이트에 엑세스하여 데이터를 얻는 과정을 "크롤링"이라고 합니다.
이런 웹 크롤러 봇은 구글이나 네이버같은 검색엔진이 운영하는데, 검색 엔진은 웹 크롤러가 수집한 데이터에 검색 알고리즘을 적용함으로써, 사용자의 검색 질의에 대한 응답으로 관련 링크를 제공합니다. 이를 통해, Google 또는 Bing 등의 검색 엔진에 검색을 입력하고 나면, 웹페이지 목록이 표시되는 것입니다.
이 크롤러는 사용자가 검색을 했을 때, 해당 페이지에 중요한 정보가 포함 될 가능성이 높은 페이지를 기준으로 웹페이지의 중요성을 판별합니다.
예를 들어 방문객이 많은지(링크를 누가 얼마나 클릭했는지), 키워드 검색과 웹페이지에 담긴 텍스트를 비교하고, 반복성, 서체 크기, 키워드 위치 등을 정보검색 기술과 연결합니다.
우리 회사 사이트가 잘 노출되게 하기 위해서는?
1. 먼저 우리 사이트 주소가 많이 링크되어있어야 합니다.
- 만약 회사가 유튜브, 인스타, 페이스북, 블로그를 가지고 있다면 회사 사이트 링크를 서로 링크를 거는 것이 중요합니다.
- 또한 각 사이트에서 제목, 내용의 단어 선택도 중요합니다.
2. <head> tag에 페이지 정보를 잘 작성해야 합니다.
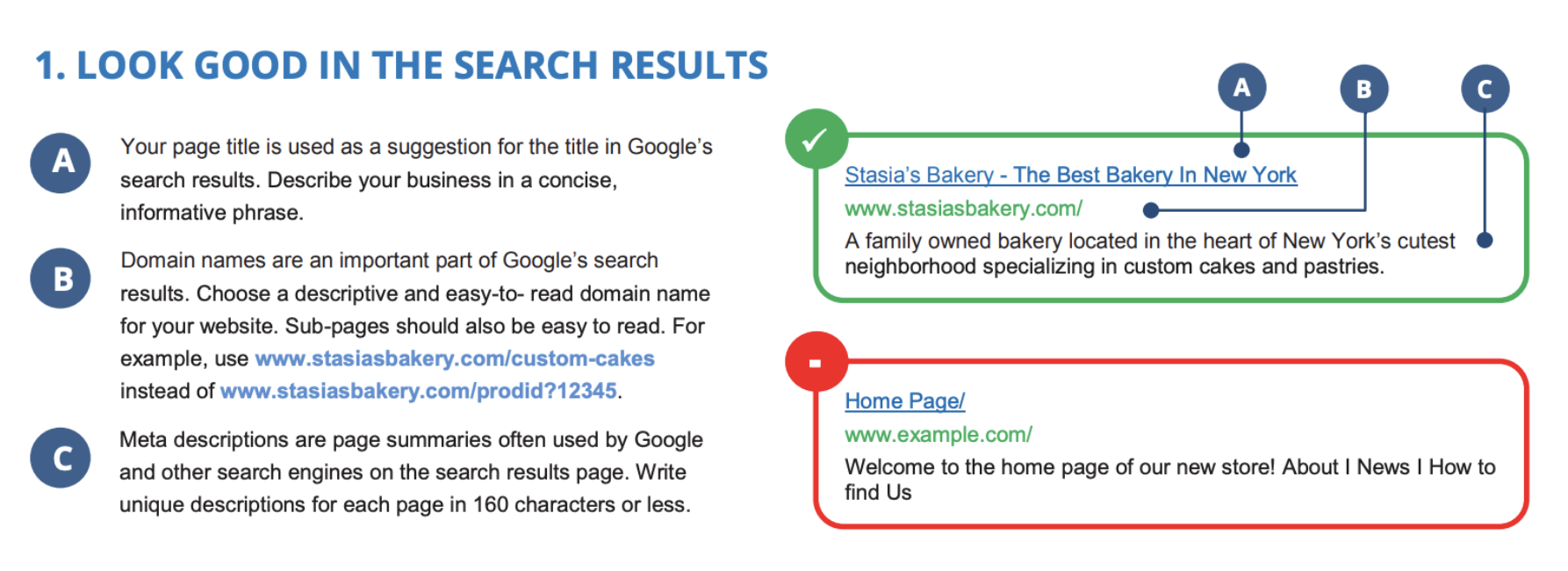
(사실 그동안은 개인 프로젝트를 하면서 title 외에는 신경을 쓰지 않았지만 이번 계기로 head 의 중요성을 알게되었답니다 😜👍)
meta tag의 description을 얼마나 잘 작성해야 하는지 이게 알게되었습니다.
실무에서 이 부분을 작성할 때 기획, 마케팅 팀이 있다면 함께 고민해봐야겠습니다.
3. robots.txt : 크롤러와 사이트의 약속
그동안 CRA를 하면서 프로젝트를 할 때 이 파일은 필요없는 파일이라 생각되어 그냥 지웠었는데, 사실 아주 중요한 파일이었습니다.
robots.txt 는 웹사이트에 대한 검색엔진 로봇들의 접근을 조절해주고 제어해주는 역할, 그리고 로봇들에게 웹사이트의 사이트맵이 어디 있는지 알려주는 역할을 합니다.
robots.txt 파일을 설정하지 않으면 구글, 네이버 등 각종 검색엔진 로봇들이 웹사이트에서 찾을 수 있는 모든 정보를 크롤링하여 검색엔진 검색결과에 노출시킵니다. 만약 웹사이트 내 특정 페이지가 검색엔진에 노출되지 않기를 바란다면 robots.txt파일을 설정하여 이를 제어할 수 있습니다.
참고 자료: https://www.twinword.co.kr/blog/basic-technical-seo/
예를 들어 admin page처럼 일반 사용자에게 보여지지 않아도 될 페이지는 크롤링을 하지 말라고 말할 수 있습니다.
사이트 페이지에서 /robots.txt를 치면 각 사이트의 약속들을 볼 수 있습니다.
저는 원티드 프리온보딩을 참여중이라서 원티드 robots.txt를 검색해 보았습니다.

아래는 네이버의 robots.txt 입니다.

4. sitemap.xml 설정
sitemap.xml은 웹사이트 내 모든 페이지의 목록을 나열한 파일로 책의 목차와 같은 역할을 합니다. 사이트맵을 제출하면 일반적인 크롤링 과정에서 쉽게 발견되지 않는 웹페이지도 문제없이 크롤링되고 색인될 수 있게 해줍니다.
컴퓨터가 이해하기 쉬운 사이트 만들기 (Semantic tag)
HTML을 가장 먼저 배울 때 Semantic tag를 통해 구조를 잡는 것을 가장 먼저 배웠습니다.
Semantic tag를 사용하면 다른 사람이 코드를 보았을 때 알아보기 쉬울 뿐 만 아니라 컴퓨터도 우리의 웹페이지를 더 잘 이해할 수 있습니다.
👉 Semantic tag => SEO, Accessibility(웹 접근성), Maintainability(유지보수)
✅ HTML5 Semantic Elements
- 페이지 이동 시 검색되길 바란다면 무조건 a 태그를 쓸 것
- <hn> 태그 잘 활용하기
- img 태그 alt 설명 잘 달기
- img 태그 사진 이름부터 잘 짓기
- img 태그 위에 figure 추가
- header, main, footer, nav, section, aside 등등 태그 잘 활용하기
- caption 태그 활용해서 table 설명쓰기
(출처: 위코드 예리님)
예를 들어 프로젝트를 하며 폰트 사이즈를 조절하기 위해 그냥 p tag를 써서 font-size 속성으로 조절했던 적이 많지 않나요?
하지만 만약 그 글씨가 title을 나타내거나 중요한 설명일 경우에는 h tag를 사용하는 것이 좋습니다.
그러면 '오 이건 제목이니까 중요한 단어가 있겠구나' 하고 컴퓨터가 더 중요도있다고 읽을 수 있습니다.
SSR 와 CSR
SEO의 중요성와 어떻게 SEO를 할 수 있는지 알아보았습니다.
그럼 이제 SSR 과 CSR이 SEO에 어떤 영향을 미치고, 어떻게 사용하는 것이 좋을지 알아보겠습니다.
SSR, CSR의 개념은 인터넷에 많이 나와있기 때문에 자세한 설명은 생략하겠습니다.
웹의 역사 & SSR & CSR
웹의 역사와 관련지어보면
1세대 웹: 정보를 보여주기 위한 기능 - 정적인 웹사이트 (HTML, CSS)
2세대 웹: Javascript의 등장으로 User Interaction 증가 - 동적인 웹 사이트
- SSR
3세대 웹: SPA 등장으로 Frontend와 backend의 구별 시작
- CSR
- 서버가 페이지 구성에 필요한 모든 요소(HTML, JavaScript, Data)를 매번 전송하는 것이 아니라, 파일은 처음 한 번만 송수신. 그 뒤로는 실시간 데이터만 주고 받음
- AJAX 등장
3세대 웹을 React와 연관지어 설명해 보겠습니다.
리액트로 프로젝트를 생성할 때 우리는 CRA를 통해 React 기반의 SPA를 구현할 수 있습니다.
그런데! CRA로 build한 프로젝트는 오로지 CSR(Client Side Render)로 실행됩니다.
👉 CSR의 특징을 간단히 살펴보면
- 웹 페이지의 렌더링이 클라이언트(브라우저) 측에서 일어나는 것을 의미.
- 브라우저는 최초 요청에서 html, js, css 확장자의 파일을 차례로 다운로드.
- 최초로 불러온 html의 내용은 비어있음. (html, body 태그만 존재)
- js 파일의 다운로드가 완료된 다음, 해당 js 파일이 dom을 빈 html 위에 그리기 시작.
- 여기서 우리는 .html 하나에 js파일로 그림
- 백엔드 호출을 최소화 할 수 있음
- 최초 호출 때만 html, js, css를 요청
- 이후에는 화면에서 변화가 일어나야 하는 만큼의 데이터만 요청 (ex. JSON)
- 라우팅(새로운 페이지로 이동)을 하더라도 html 자체가 바뀌는 것이 아니라 JavaScript 차원에서 새로운 화면을 그려내는 것!
그런데 여기서 하나의 .html파일을 가질 때 가장 처음에는 파일에 bodt tag 하나만 들어있는 첫 페이지 깡통이 되는 상태가 됩니다.
이런 특성 때문에 웹 크롤러에서 CSR로 구성된 페이지를 접속하면 우리 페이지들이 검색 노출이 잘 안되게 되는 것이지요.
하지만 SSR을 할 경우, 서버에서 첫 페이지를 랜더링 해줍니다.
SSR 은 CSR보다 SEO 측면에서 유리합니다.
서버에서 사용자에게 보여줄 페이지를 모두 구성 한 다음 사용자에게 보여주기 때문에 CSR의 단점인 깡통 페이지 극복을 할 수 있다는 장점이 있습니다.

또한 전체적으로 사용자에게 보여주는 콘텐츠 구성이 CSR보다 빠르게 완료된다는 UX 측면에서도 유리한 장점이 있습니다.
(그러나 페이지를 잘못 구성 할 경우에는 서버 부하가 커지거나 첫페이지 로딩이 매우 느려질 수 있습니다.)
그렇게 우리는 CSR와 SSR를 조합하여 CSR의 장점을 사용하면서도 SEO을 극복할 수 있는 방안을 생각해보게 되었습니다.
아! 그럼 SSR을 사용하는 이유는 오직 SEO를 위해 사용하는 것인가요? 라는 질문에 네! 라고 대답할 수 있습니다.
SPA for SSR
CSR와 SSR을 합칠 경우 장점을 말하자면 저는 크~게 아래처럼 말할 수 있을 것입니다.
- html 파일이 한개이다. (CSR)
- 페이지 이동 시 화면의 깜박임이 없다. (CSR)
- 페이지 기반 라우팅 시스템 (동적 라우팅 지원) (CSR)
- SEO를 고려하여 페이지를 만들 수 있다 (SSR)
이 방법을 사용할 수 있는 방법이 바로 Next.js입니다.
만약 Vue.js를 사용한 프로젝트라면 Nuxt.js 라이브러리를 사용할 수 있습니다.
이상으로 SEO를 위한 CSR과 SSR의 특징을 이해해 보았습니다.
라이브러리를 그냥 사용하는 것 보다 왜 이렇게 등장하게 되었는지, React에서 CRA를 할 때 파일 구조가 왜 이렇게 구성되는지 head의 중요성 등을 더 깊게 생각하고 이해할 수 있는 기회가 되었습니다. :)
(참고 자료 링크)
https://blueshw.github.io/2018/04/15/why-nextjs/
https://www.cloudflare.com/ko-kr/learning/bots/what-is-a-web-crawler/
'Web' 카테고리의 다른 글
| 브라우저가 사용자에게 홈페이지를 보여주는 방법 (0) | 2023.02.20 |
|---|---|
| 내가 알던 REST API는 새 발의 피였떵 (0) | 2023.02.18 |
| HTTP, HTTPS의 차이점 (0) | 2021.06.23 |
| 함수형 프로그래밍 (0) | 2021.06.19 |
| REST API란? (0) | 2021.06.18 |



